Apple shows its latest AI system GAUDI. It can generate 3D indoor scenes and is the foundation for a new generation of generative AI based on NeRFs.
So-called neural rendering brings artificial intelligence to computer graphics: AI researchers at Nvidia, for example, are showing how 3D objects are created from photos, and Google is relying on Neural Radiance Fields (NeRFs) for Immersive View or developing NeRFs for rendering people.
So far, NeRFs are mainly used as a kind of neural storage medium for 3D models and 3D scenes, which can then be rendered from different camera perspectives. This is how the frequently shown camera movements through a room or around an object are created. Initial experiments with NeRFs for virtual reality experiences are also underway.
NeRFs could become the next stage of generative artificial intelligence
But what if NeRF's ability to render images photorealistically and from different angles could be used for generative AI? AI systems like OpenAI's DALL-E 2 or Google's Imagen and Parti show the potential of controllable generative AI, but only for 2D images and graphics.
Google gave the first glimpse of 3D AI generation in late 2021 with Dream Fields, an AI system that combines NeRF's ability to generate 3D views with OpenAI's CLIP's ability to evaluate content from images. The result: Dream Fields generates NeRFs that match text descriptions.
Now Apple's AI team is introducing GAUDI, a neural architecture for immersive 3D scene generation. The AI system can create 3D scenes based on text prompts.
Apple GAUDI is a specialist for 3D interiors
While Google, for example, is dedicated to generating individual objects with Dream Fields, extending generative AIs to fully unconstrained 3D scenes remains an as-yet unsolved problem.
One reason for this is the limitation of possible camera positions: While for a single object, every possible reasonable camera position can be mapped to a dome, in 3D scenes these camera positions are limited by obstacles like objects and walls. If these are not considered during scene generation, the generated 3D scene is not usable.
Apple's GAUDI model solves this problem with three specialized networks: a camera pose decoder makes predictions for possible camera positions and ensures that the output is a valid position for the architecture of the 3D scene.

The scene decoder for the scene predicts a tri-plane representation, which is a kind of 3D canvas on which the radiance field decoder draws the subsequent image using the volumetric rendering equation.
In experiments with four different datasets, including ARKitScences, a dataset of indoor scans, the researchers show that GAUDI can reconstruct learned views and matches the quality of existing approaches.
Video: Miguel Angel Bautista via Twitter
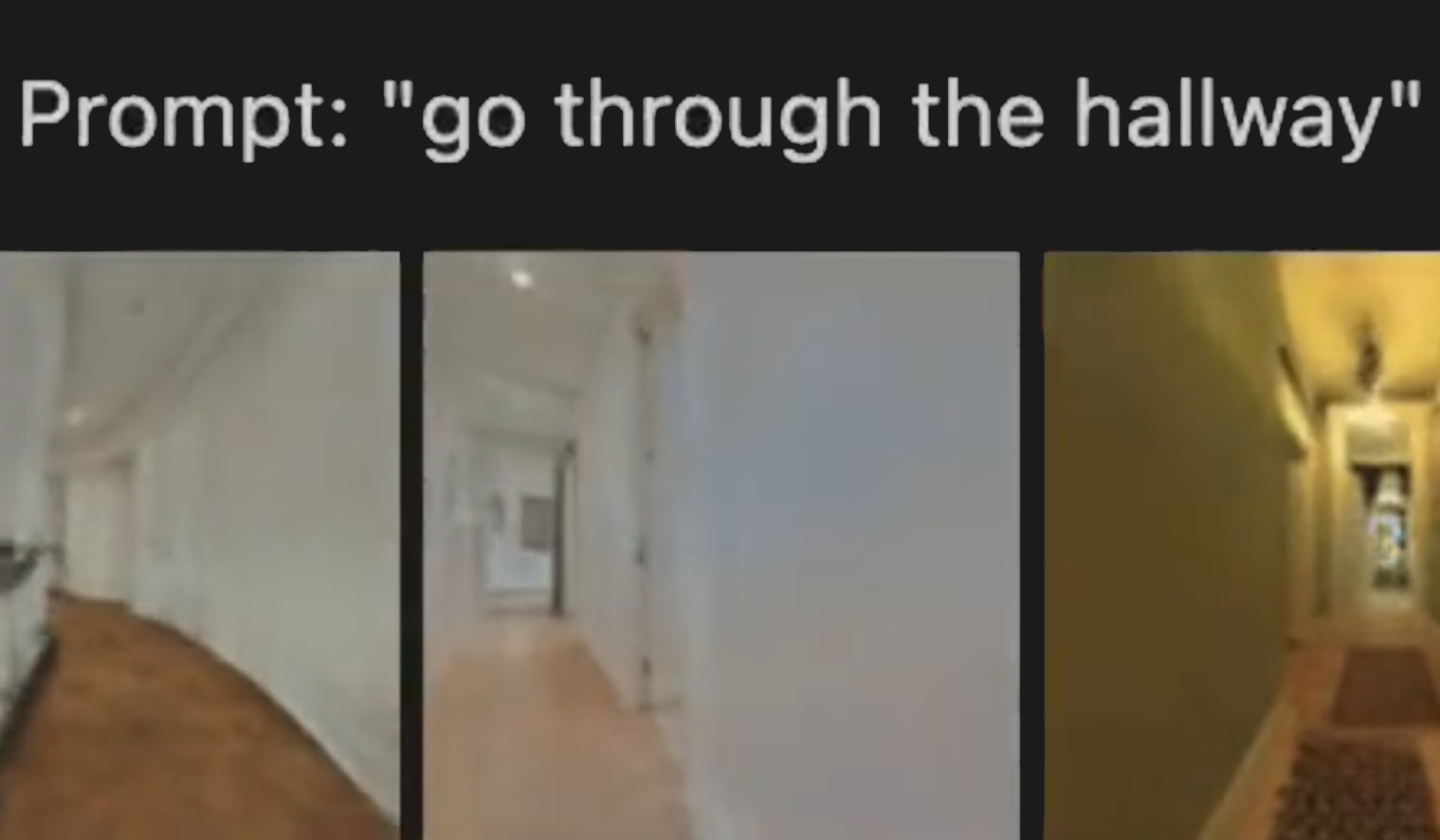
Apple also demonstrates that GAUDI can generate new camera movements through 3D indoor scenes. The generation can be random, start from an image or be controlled by text input with a text encoder - for example, "go through the hallway" or "go up the stairs".
The quality of video generated by GAUDI is still low and filled with artifacts. But with its AI system, Apple is laying another foundation for generative AI systems that can render 3D objects and scenes. One possible application: generating digital locations for Apple's XR headset.
Excited for this to be out! Introducing GAUDI: a generative model for 3D indoor scenes. We tackle the problem of learning a generative model of 3D scenes parametrized as radiance fields. This has been a great collaboration across multiple teams at @Apple. https://t.co/aJOqtzA2CI https://t.co/tSkJdXK31C pic.twitter.com/ReeXAPGg95
- Miguel Angel Bautista (@itsbautistam) July 29, 2022




