
Deepmind's Flamingo combines a visual AI model with a language model. The aim is for artificial intelligence to gain a better visual understanding.
Large language models like OpenAI's GPT-3 are few-shot learners: they learn to perform a task based on a few examples. If GPT-3 is to translate German into English, for example, the model can be set up accordingly with two to three example translations.
This few-shot learning works because GPT-3 has been pretrained with countless data. The few-shot training with a couple of examples is then simply a form of fine-tuning.
Deepmind is now demonstrating Flamingo, an AI system that combines a language model and a visual model and performs image analysis using few-shot learning.
Deepmind Flamingo relies on Chinchilla and Perceiver
Instead of text-only examples, Flamingo's visual language model processes image-text pairs, such as questions and expected responses to an image. The model can then answer questions about new images or videos.
As an example, Deepmind cites the identification and counting of animals, such as three zebras in an image. A traditional visual model that is not coupled with a language model would have to be re-trained with thousands of example images to accomplish this task. Flamingo, on the other hand, requires only a few example images with matching text output.
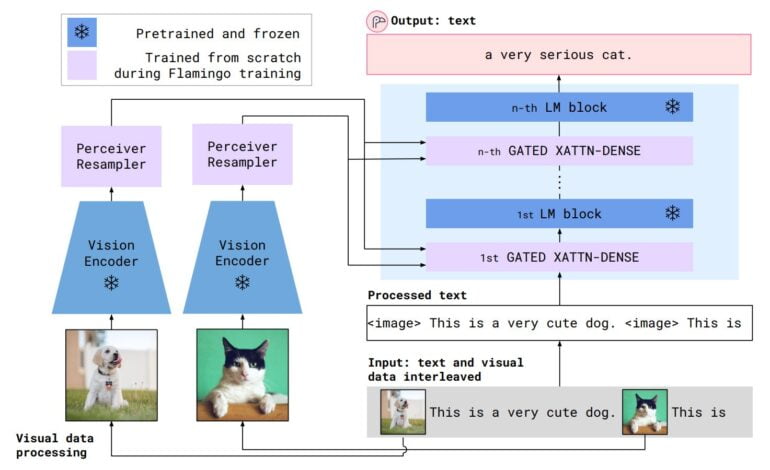
Flamingo connects a ResNet encoder trained with images and text to a variant of Deepmind's Chinchilla language model. The connection is enabled by Deepmind's Perceiver, which processes the output of the visual model and passes it to the attention layer before the language model.
During Flamingo training, the pretrained visual model and the language model are frozen to preserve their abilities. Only the perceptual and attentional layers are trained.
Flamingo shows basic image comprehension
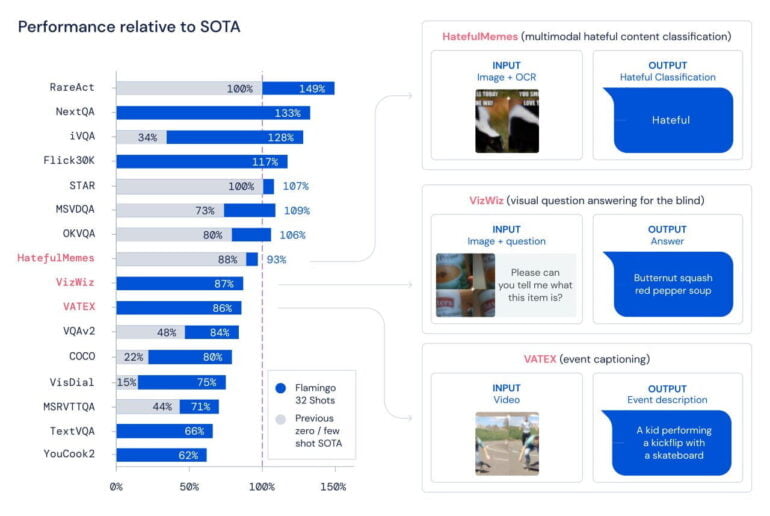
In 16 image understanding benchmarks tested, Flamingo beats other few-shot approaches. In these tests, Flamingo has to recognize hate speech on memes, identify and describe objects, or name events in a video, for example. With only 32 examples and no adjustment of weights in the models, Flamingo also outperforms current best practices in seven tasks that have been fine-tuned with thousands of annotated examples.

Flamingo can also carry on more or less meaningful conversations and process information from pictures and texts. In dialog with a human, for example, the model can correct itself independently when prompted to do so by pointing out a possible error.
Video: Deepmind
According to the researchers, the results represent an important step toward a general visual understanding of artificial intelligence. However far this road may be, linking large AI models for multimodal tasks is likely to play an essential role.





